Syväoppiminen: mikä se on? Neuroverkot, toiminta ja esimerkit
Syväoppiminen: opas neuroverkkojen toimintaan, esimerkkeihin ja sovelluksiin—kuinka monikerroksiset mallit tunnistavat kuvia, puhetta ja tekstiä.
Syväoppiminen (jota kutsutaan myös syvärakenteiseksi oppimiseksi tai hierarkkiseksi oppimiseksi) on eräänlainen koneoppimisen muoto, jota käytetään lähinnä tietynlaisten neuroverkkojen kanssa. Kuten muissakin koneoppimisen lajeissa, oppimisjaksot voivat olla valvomattomia, puolivalvottuja tai valvottuja. Monissa tapauksissa rakenteet on järjestetty siten, että syöttökerroksen ja lähtökerroksen välissä on vähintään yksi välikerros (tai piilokerros).
Tietyt tehtävät, kuten puheen, kuvien tai käsialan tunnistaminen ja ymmärtäminen, ovat ihmisille helppoja. Tietokoneelle nämä tehtävät ovat kuitenkin hyvin vaikeita. Monikerroksisessa neuroverkossa (jossa on enemmän kuin kaksi kerrosta) käsiteltävästä tiedosta tulee abstraktimpaa jokaisen lisätyn kerroksen myötä.
Syväoppimismallit perustuvat biologisten hermojärjestelmien tiedonkäsittely- ja viestintämalleihin; ne eroavat monin tavoin biologisten aivojen (erityisesti ihmisaivojen) rakenteellisista ja toiminnallisista ominaisuuksista, minkä vuoksi ne eivät ole yhteensopivia neurotieteiden todisteiden kanssa.
Kuvagalleria
3 Kuvat
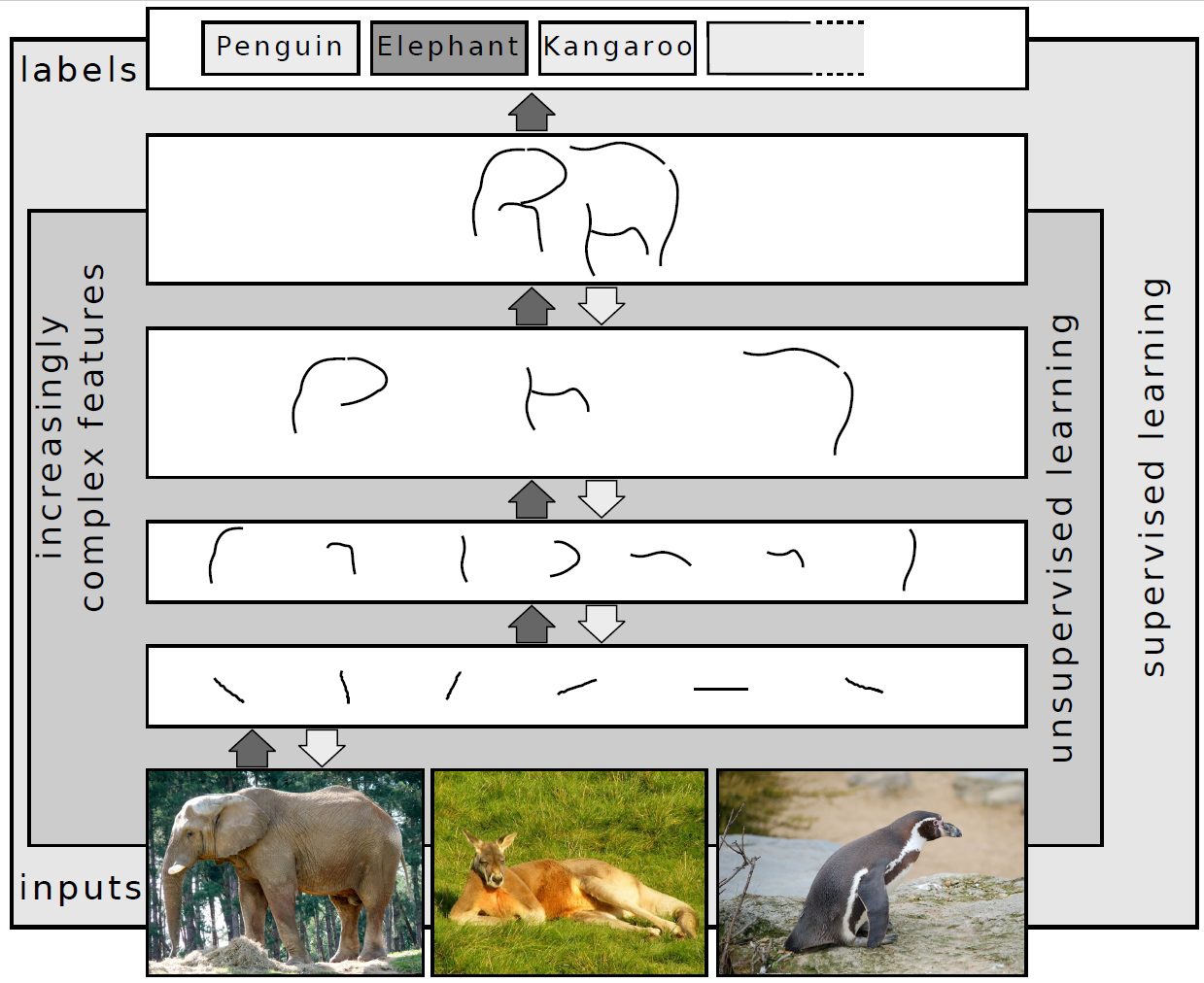
Miten neuroverkot toimivat?
Syväoppimisen perusyksikkö on keinotekoinen neuroni, joka vastaanottaa tuloja, painottaa niitä väkeillä (painokertoimilla), summaa ne ja lähettää tulon aktivointifunktion läpi seuraavalle kerrokselle. Oppiminen tapahtuu muuttamalla näitä painokertoimia siten, että verkon tuottama ennuste vastaa mahdollisimman hyvin tavoitteita. Keskeiset käsitteet:
- Etusijoitus (forward pass) — syötteen eteneminen verkon läpi ennusteeksi.
- Häviöfunktio (loss) — mittari, joka kertoo, kuinka paljon ennuste poikkeaa todellisesta arvosta.
- Takaisinlevitys (backpropagation) — menetelmä, jolla lasketaan häviön gradientit ja päivitetään painot.
- Optimointi (esim. gradient descent, Adam) — algoritmit, jotka muuttavat painoja oppimisessa.
- Hyperparametrit — oppimisnopeus, eräkoko (batch size), verkon syvyys ja muut asetukset, jotka vaikuttavat oppimiseen.
Tyypillisiä arkkitehtuureja
- Täydet yhdistelmät (MLP, Fully Connected) — yksinkertaisin tyyppi, usein lähtökohtana pienissä tehtävissä.
- Konvoluutioneuroverkot (CNN) — erityisen tehokkaita kuvien ja paikallisen rakenteen tunnistuksessa (reunat, muodot).
- Toistoverkot (RNN), LSTM ja GRU — suunniteltu käsittelemään sekvenssejä kuten tekstiä tai aikasarjoja.
- Transformerit — nykyaikainen arkkitehtuuri, joka perustuu attention-mekanismeihin; tämän avulla syntyvät tehokkaat kielimallit ja monia muita sovelluksia.
- Autokooderit, Variational Autoencoders (VAE) ja Generative Adversarial Networks (GAN) — käytetään tiedon pakkaamiseen ja generointiin.
Sovellusesimerkkejä
- Kuvantunnistus ja luokittelu (esim. kasvien, esineiden tai sairauden tunnistus röntgenkuvista)
- Puheentunnistus ja puhesynteesi
- Luonnollisen kielen käsittely (konekäännös, tekstin luokittelu, kysymys-vastausjärjestelmät)
- Autonominen liikenne ja konenäkö
- Suositusjärjestelmät ja käyttäytymisen mallintaminen
- Sisällön generointi (kuvat, teksti, ääni) ja luova tekoäly
Oppimisen tyypit ja datan merkitys
Syväoppimisessa voidaan käyttää erilaisia oppimistapoja:
- Valvottu oppiminen — malli oppii syöte–tulos-pareista (esim. kuvan ja luokan välillä).
- Valvomaton oppiminen — malli etsii rakenteita ilman selkeitä tunnisteita (esim. klusterointi, ominaisuuksien oppiminen).
- Puolivalvottu oppiminen — yhdistää pienen määrän merkittyä dataa suureen määrään merkitsemätöntä.
- Vahvistusoppiminen — malli oppii toimimaan ympäristössä saamalla palkintoja tai rangaistuksia.
Datan määrä ja laatu ovat usein tärkein menestyksen tekijä syväoppimisessa. Esikoulutus (pretraining) ja siirto-oppiminen (transfer learning) helpottavat mallien käyttöönottoa, kun saatavilla on rajallisesti merkittyä dataa.
Haasteet ja rajoitukset
- Datantarve: syväverkot vaativat usein suuria, monipuolisia datasetit toimiakseen hyvin.
- Laskentateho ja energiankulutus: koulutus voi olla kallista ja hidasta ilman tehokasta laitteistoa (GPU, TPU).
- Tulkittavuus: syvät mallit ovat usein "mustia laatikoita" — niiden päätöksiä voi olla vaikea selittää.
- Yläsovitus (overfitting): malli voi oppia liikaa koulutusdataa eikä yleisty hyvin.
- Bias ja eettiset ongelmat: data voi sisältää vinoutumia, jotka siirtyvät mallin ennusteisiin.
- Haavoittuvuus: mallit voivat olla herkkiä pehmeisiin muutoksiin tai hyökkäyksille (adversarial attacks).
- Vaikka syväoppimismallit ovat innoittuneet biologisista hermojärjestelmistä, niiden toiminta poikkeaa monin tavoin todellisista aivoista, eikä niiden käyttö sellaisenaan korvaa neurotieteellistä ymmärrystä.
Työkalut ja käytännön vinkkejä aloittelijalle
- Hyviä kirjastoja: TensorFlow, Keras, PyTorch sekä lisäksi scikit-learn perusasioihin.
- Aloita pienestä: käytä valmiita, pienempiä datasettiä ja esikoulutettuja malleja ennen suurten mallien rakentamista.
- Seuraa suorituskykyä erillisen testijoukon avulla ja käytä ristiinvalidointia yleistyvyyden arviointiin.
- Hyödynnä visualisointityökaluja (esim. TensorBoard) ja metrikat (loss, accuracy, precision/recall) virheiden ymmärtämiseen.
- Kokeile erilaisia optimointimenetelmiä, säädä oppimisnopeutta ja lisää regularisointia (dropout, weight decay) ylisovittamisen estämiseksi.
Yhteenvetona: syväoppiminen on voimakas joukko menetelmiä monimutkaisten havaintojen ja rakenteiden oppimiseen, erityisesti kun dataa ja laskentatehoa on runsaasti. Menestykseen tarvitaan oikeanlainen arkkitehtuuri, huolellinen datan käsittely ja ymmärrys menetelmien rajoituksista sekä eettisistä näkökohdista.

Kysymyksiä ja vastauksia
K: Mitä on syväoppiminen?
V: Syväoppiminen on eräänlainen koneoppimisen muoto, jossa käytetään neuroverkkoja tiedon käsittelyyn, ja se on usein organisoitu siten, että tulo- ja lähtökerrosten välissä on vähintään yksi väli- (piilotettu) kerros.
K: Mitä erilaisia oppimisjaksoja syväoppimisessa käytetään?
V: Syväoppiminen voidaan jakaa valvomattomiin, puolivalvottuihin ja valvottuihin oppimisistuntoihin.
K: Mitkä ovat tehtäviä, jotka ovat ihmisille helppoja mutta tietokoneille vaikeita suorittaa?
V: Tehtävät, kuten puheen, kuvien tai käsialan tunnistaminen ja ymmärtäminen, ovat ihmisille helppoja mutta tietokoneille vaikeita.
K: Mitä tiedolle tapahtuu, kun sitä käsitellään monikerroksisessa neuroverkossa?
V: Monikerroksisessa neuroverkossa käsiteltävästä tiedosta tulee abstraktimpaa jokaisen lisätyn kerroksen myötä.
K: Mistä syväoppimisen mallit ovat saaneet vaikutteita?
V: Syväoppimisen mallit ovat saaneet vaikutteita biologisten hermojärjestelmien tiedonkäsittely- ja viestintämalleista.
K: Miten syväoppimismallit eroavat biologisten aivojen ominaisuuksista?
V: Syväoppimismallit eroavat monin tavoin biologisten aivojen, erityisesti ihmisaivojen, rakenteellisista ja toiminnallisista ominaisuuksista, mikä tekee niistä yhteensopimattomia neurotieteellisten todisteiden kanssa.
K: Mikä on toinen termi syväoppimiselle?
V: Syväoppiminen tunnetaan myös nimellä syvä strukturoitu oppiminen tai hierarkkinen oppiminen.
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Syväoppiminen: mikä se on? Neuroverkot, toiminta ja esimerkit Leandro Alegsa
URL: https://fi.alegsaonline.com/art/26216
Lähteet
- ncbi.nlm.nih.gov : "Toward an Integration of Deep Learning and Neuroscience"
- doi.org : 10.3389/fncom.2016.00094
- pubmed.ncbi.nlm.nih.gov : 27683554
- ui.adsabs.harvard.edu : 1996Natur.381..607O
- doi.org : 10.1038/381607a0
- pubmed.ncbi.nlm.nih.gov : 8637596