Superskalaarinen suoritin – määritelmä, toiminta ja ominaisuudet
Superskalaarinen suoritin — määritelmä, toiminta ja ominaisuudet: miten rinnakkaisuus ja pipelointi parantavat CPU:n suorituskykyä.
Superskalaarisen suorittimen suunnittelussa yhden suorittimen sisällä käytetään rinnakkaislaskennan muotoa, jota kutsutaan käskytason rinnakkaistoiminnaksi ja jonka ansiosta samalla kellotaajuudella voidaan tehdä enemmän työtä. Tämä tarkoittaa sitä, että CPU suorittaa useamman kuin yhden käskyn kellojakson aikana suorittamalla useita käskyjä samanaikaisesti (ns. käskynjako) päällekkäisissä toiminnallisissa yksiköissä. Kukin funktionaalinen yksikkö on vain suorittimen ytimen sisällä oleva suoritusresurssi, kuten aritmeettinen logiikkayksikkö (ALU), liukulukuyksikkö (FPU), bittisiirrin tai kerroin.
Useimmat superskalaariset suorittimet ovat myös putkijohdettuja, mutta on mahdollista, että on olemassa myös ei-pipeloitu superskalaarinen suoritin tai putkijohdettu ei-superskalaarinen suoritin.
Superskalaarista tekniikkaa tuetaan useilla suorittimen ytimen ominaisuuksilla:
- Ohjeet tulevat järjestetystä ohjeluettelosta.
- Suoritinlaitteisto voi selvittää, millä ohjeilla on mitäkin datariippuvuuksia.
- Voi lukea useita ohjeita kellojaksoa kohti
Jokainen skalaariprosessorin suorittama käsky muuttaa yhtä tai kahta datatietoa kerrallaan, mutta jokainen vektoriprosessorin suorittama käsky käsittelee useita datatietoja kerralla. Superskalaarinen prosessori on näiden kahden sekoitus:
- Kukin ohje käsittelee yhtä datatietoa.
- Jokaisessa suorittimen ytimessä on useita päällekkäisiä toiminnallisia yksiköitä, joten useat ohjeet käsittelevät samanaikaisesti riippumattomia tietoelementtejä.
Superskalaarisessa suorittimessa käskyjen jakelija lukee käskyt muistista ja päättää, mitkä käskyt voidaan suorittaa rinnakkain, ja jakaa ne suorittimessa käytettävissä oleviin moninkertaisiin toiminnallisiin yksiköihin.
Superskalaarisen suorittimen suunnittelussa pyritään parantamaan käskynjakajan tarkkuutta ja antamaan sille mahdollisuus pitää useat toiminnalliset yksiköt koko ajan kiireisinä. Vuodesta 2008 lähtien kaikki yleiskäyttöiset suorittimet ovat superskalaarisia, ja tyypillisessä superskalaarisessa suorittimessa voi olla jopa neljä ALU:ta, kaksi FPU:ta ja kaksi SIMD-yksikköä. Jos dispatcher ei pysty pitämään kaikkia yksiköitä kiireisinä, suorittimen suorituskyky heikkenee.
Kuvagalleria
2 Kuvat
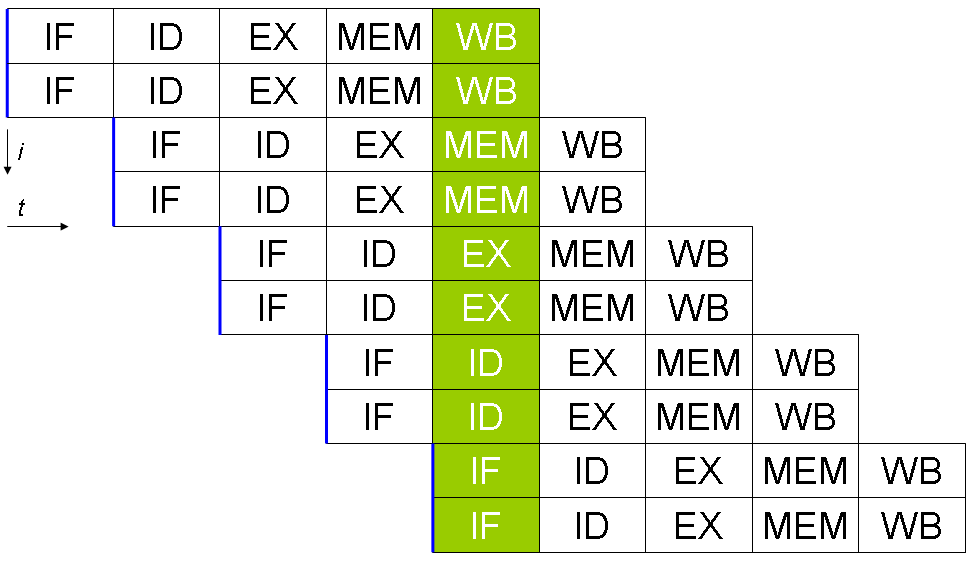
Miten superskalaarinen suoritin toimii käytännössä?
Superskalaarinen suoritin pyrkii kasvattamaan käskyjen suoritusmäärää per kellosyklinen suoritus (instructions per cycle, IPC) jakamalla suoritusputken useisiin rinnakkaisiin polkuihin. Perusvaiheet ovat:
- Haun ja dekoodauksen laajentaminen niin, että useampi käsky haetaan ja dekoodataan samanaikaisesti.
- Riippuvuusanalyysi: laitteisto tai ohjelma tarkistaa, mitkä käskyt riippuvat toisistaan.
- Jakaminen (dispatch/issue): pätevät ja riippumattomat käskyt lähetetään vapaisiin funktionaalisiin yksiköihin.
- Suoritus: käsky suoritetaan sen omassa yksikössä.
- Commit/Write-back: tulokset kirjoitetaan arkkitehtonisiin rekistereihin ohjeiden järjestyksessä (riippuen arkkitehtuurista).
Monimutkaisemmat superskalaarit tukevat myös out-of-order-suoritusta: käskyt voidaan suorittaa eri järjestyksessä kuin ohjelmassa, kunhan riippuvuudet ja näkyvyys säilyvät oikein. Tällöin tarvitaan mekanismeja, kuten rekisterien uudelleen nimeäminen (register renaming) ja reorder buffer, jotta suorituksen lopputulos vastaa ohjelman määrittelyä.
Keskeiset tekniikat ja komponentit
- Käskynhakunopeus ja dekooderi — jos haetaan ja dekoodataan vain yksi käsky kerrallaan, ei ole paljon rinnakkaisuutta hyödynnettävänä. Laajemmat hakupuskuroinnit ja leveämmät dekooderit ovat tärkeitä.
- Riippuvuuksien tunnistus — laitteisto tarkistaa data-, control- ja structural-riippuvuudet, jotta ei synny kilpailua samoista resursseista.
- Rekisterien uudelleen nimeäminen — estää WAR- ja WAW-tyyppisiä ongelmia (write-after-read / write-after-write) ja mahdollistaa tehokkaamman rinnakkaisuuden.
- Out-of-order -suoritus ja commit — suorituksen järjestyksen hallinta ja näköjään järjestyksessä tapahtuva lopullinen läpivienti (commit) säilyttävät arkkitehtonisen tilan oikeana.
- Branch prediction — haarojen ennustaminen on kriittinen, koska haarat katkaisevat käskyvirran; hyvät ennustimet pienentävät putken tyhjäkäyntejä.
- Reorder buffer, reservation stations ja Tomasulo-tyyliset mekanismit — auttavat käskyjen ajoituksessa, riippuvuuksien hallinnassa ja tulosten välittämisessä turvallisesti.
- Simultaneous multithreading (SMT) — kuten Hyper-Threading, voi täyttää toiminnallisia yksiköitä ajoittain eri säikeiden käskyillä.
Edut ja rajoitukset
Edut:
- Suurempi IPC eli parempi suorituskyky samalla kellotaajuudella.
- Hyvä hyötysuhde, kun ohjelmassa on paljon riippumattomia käskyjä.
- Mahdollistaa monipuolisemman resurssien käytön: ALU:t, FPU:t ja SIMD-yksiköt voidaan pitää aktiivisina.
Rajoitukset ja haasteet:
- Riippuvuudet — runsaat datariippuvuudet rajoittavat rinnakkaisuuden määrää.
- Ohjelman luonne — harvat rinnakkaiset käskyt (esim. paljon peräkkäisiä riippuvuuksia) estävät hyödyntämisen.
- Kustannus ja monimutkaisuus — laitteiston tarpeet (ennustus, uudelleen nimeäminen, varausasemat, reorder buffer) kasvattavat piirin kokoa ja energian kulutusta.
- Haarojen ennustamisen virheet — epäonnistuneet ennusteet tuhoavat dekoodattujen ja osittain suoritettujen käskyjen edut ja aiheuttavat viivettä.
Arkkitehtonisia huomioita ja vertailu
- Superskalaarisuus vs. VLIW — VLIW-arkkitehtuureissa (Very Long Instruction Word) rinnakkaisuus määräytyy pääosin kompilointivaiheessa, kun taas superskalaarissa laitteisto tekee päätökset dynaamisesti. Tämä tekee VLIW:stä usein yksinkertaisemman laitteistollisesti, mutta vaatii älykkäämpää käännöstekniikkaa.
- Putkijohdotus — useimmat superskalaarit ovat myös putkijohdettuja; putkijohdotuksen ja superskalaarisuuden yhdistelmä tuo suurimman hyödyn, mutta myös lisää koordinoinnin tarvetta.
- Moniydin- ja heterogeeniset rakenteet — modernit järjestelmät yhdistävät superskalaarisuutta moniytimisyyteen ja erityyppisiin laskentayksiköihin (esim. SIMD, GPU), mikä parantaa suorituskykyä eri kuormissa.
Suorituskyvyn mittarit
- IPC (instructions per cycle) — keskeinen mittari, joka kertoo kuinka monta käskyä suoritetaan keskimäärin per kellosyklissä.
- Issue width — kuinka monta käskyä laite voi jakaa (issue) yhdellä kellojaksolla (esim. 2-way, 4-way, 8-way).
- Keskimääräinen putken täyttöaste — kuinka usein funktionaaliset yksiköt ovat aktiivisina.
Historia ja esimerkit
Superskalaarisuus on ollut keskeinen suunta grafi- ja yleiskäyttöisten suorittimien kehityksessä 1980–1990-luvuilta lähtien. Monet kaupalliset mikroarkkitehtuurit yhdistävät superskalaarisia ominaisuuksia, putkijohdotusta, haaranennustusta ja out-of-order -suoritusta. Nykyään lähes kaikki yleiskäyttöiset x86- ja RISC-suunnittelut ovat superskalaarisia osana monimutkaista mikroarkkitehtuuria.
Käytännön vinkkejä ohjelmoijalle
- Kirjoita koodia, joka mahdollistaa riippumattomien käskyjen esiintymisen — esimerkiksi vältä turhia rekisteririippuvuuksia ja hajauta riippuvat laskut eri vaiheisiin.
- Hyödynnä kompilaattorin optimointeja, jotka tuottavat rinnakkaisuutta hyödyntävää koodia.
- Jos suoritat numeerista laskentaa, SIMD- ja FPU-resurssit kannattaa ottaa huomioon; tietyt algoritmit hyötyvät erityisesti näiden rinnakkaisuudesta.
Yhteenvetona superskalaarinen suoritin parantaa suorituskykyä käyttämällä rinnakkaisia funktionaalisia yksiköitä yhden ytimen sisällä. Menestyksellinen toteutus vaatii kuitenkin monia tukimekanismeja riippuvuuksien hallinnasta haaranennustukseen ja rekisterien uudelleen nimeämiseen. Vaikka tekniikka on monimutkainen, se on olennainen osa modernien suorittimien tehokkuutta ja suorituskykyä.


Rajoitukset
Suorituskyvyn parantamista superskalaarisen suorittimen suunnittelussa rajoittaa kaksi asiaa:
- Käskylistan sisäänrakennetun rinnakkaisuuden taso
- Lähetysjärjestelmän ja tietojen riippuvuuden tarkistamisen monimutkaisuus ja aikakustannukset.
Vaikka riippuvuuksien tarkistaminen olisi äärettömän nopeaa normaalissa superskalaarisessa suorittimessa, jos käskyluettelossa itsessään on paljon riippuvuuksia, tämä rajoittaa myös mahdollista suorituskyvyn parantumista, joten koodin sisäänrakennettu rinnakkaisuus on toinen rajoitus.
Riippumatta siitä, kuinka nopea lähetysnopeus on, on olemassa käytännön rajoitus sille, kuinka monta ohjetta voidaan lähettää samanaikaisesti. Vaikka laitteiston kehittyminen mahdollistaa useampien toiminnallisten yksiköiden (esim. ALU:iden) käytön CPU-ydintä kohti, käskyriippuvuuksien tarkistamisen ongelma kasvaa niin suureksi, että saavutettavissa oleva superskalaarinen lähetysraja on jokseenkin pieni. -- Todennäköisesti noin viidestä kuuteen samanaikaisesti lähetettävää ohjetta.
Vaihtoehdot
- Samanaikainen monisäikeistäminen (Simultaneous multithreading, usein lyhenne SMT) on tekniikka, jolla parannetaan superskalaaristen suorittimien kokonaisnopeutta. SMT mahdollistaa useiden toisistaan riippumattomien suoritussäikeiden käytön, jolloin nykyaikaisen superskaalisen prosessorin resursseja voidaan hyödyntää paremmin.
- Moniydinprosessorit: Superskalaariset prosessorit eroavat moniydinprosessoreista siinä, että useat redundantit toiminnalliset yksiköt eivät ole kokonaisia prosessoreita. Yksittäinen superskalaarinen prosessori koostuu kehittyneistä toiminnallisista yksiköistä, kuten ALU:sta, kokonaislukukertoimesta, kokonaisluvunsiirtimestä, liukulukuyksiköstä (FPU) jne. Kustakin toiminnallisesta yksiköstä voi olla useita versioita, jotta monia käskyjä voidaan suorittaa rinnakkain. Tämä eroaa moniydinprosessoreista, jotka käsittelevät samanaikaisesti useiden säikeiden ohjeita, yksi säie per ydin.
- Putkipohjaiset prosessorit: Superskalaariset prosessorit eroavat myös putkipohjaisesta suorittimesta, jossa useat käskyt voivat olla samanaikaisesti eri suoritusvaiheissa.
Vaihtoehtoiset tekniikat eivät sulje toisiaan pois - ne voidaan yhdistää (ja usein yhdistetäänkin) yhdessä prosessorissa, joten on mahdollista suunnitella moniydinsuoritin, jossa jokainen ydin on itsenäinen prosessori, jossa on useita rinnakkaisia superskalaarisia putkistoja. Joissakin moniydinprosessoreissa on myös vektorikyky.
Aiheeseen liittyvät sivut
- Rinnakkaislaskenta
- Käskytason rinnakkaisuus
- Samanaikainen monisäikeistäminen (SMT)
- Moniydinprosessorit
Kysymyksiä ja vastauksia
K: Mitä on superskalaarinen teknologia?
V: Superskalaaritekniikka on rinnakkaislaskennan perusmuoto, joka mahdollistaa useamman kuin yhden käskyn käsittelyn kussakin kellojaksossa käyttämällä useita suoritusyksiköitä samanaikaisesti.
K: Miten superskalaaritekniikka toimii?
V: Superskalaaritekniikkaan kuuluu, että käskyt tulevat prosessoriin järjestyksessä, että prosessorin suorituksen aikana etsitään datariippuvuuksia ja että jokaisessa kellosyklissä ladataan useampi kuin yksi käsky.
K: Mitä eroa on skalaari- ja vektoriprosessoreilla?
V: Skalaariprosessorissa ohjeet käsittelevät yleensä yhtä tai kahta tietoa kerralla, kun taas vektoriprosessorissa ohjeet käsittelevät yleensä useita tietoja kerralla. Superskalaarinen prosessori on sekoitus molempia, sillä kukin käsky käsittelee yhtä datakohtaa, mutta useampi kuin yksi käsky suoritetaan kerralla, joten prosessori käsittelee useita datakohteita kerralla.
Kysymys: Mikä on tarkan käskynjakajan rooli superskalaarisessa prosessorissa?
V: Tarkka käskynjakelulaite on erittäin tärkeä superskaalarisessa prosessorissa, koska se varmistaa, että suoritusyksiköt ovat aina varattuja todennäköisesti tarvittavien töiden kanssa. Jos käskynjakelija ei ole tarkka, osa työstä saatetaan joutua heittämään pois, jolloin prosessori ei ole nopeampi kuin skaalautuva prosessori.
Kysymys: Minä vuonna kaikista tavallisista suorittimista tuli superskalaarisia?
V: Kaikista tavallisista suorittimista tuli superskalaattoreita vuonna 2008.
K: Kuinka monta ALU-, FPU- ja SIMD-yksikköä voi olla tavallisessa suorittimessa?
V: Tavallisessa suorittimessa voi olla enintään 4 ALU:ta, 2 FPU:ta ja 2 SIMD-yksikköä.
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Superskalaarinen suoritin – määritelmä, toiminta ja ominaisuudet Leandro Alegsa
URL: https://fi.alegsaonline.com/art/95080