Mikroarkkitehtuuri – prosessorin sisäinen rakenne ja toimintaperiaate
Mikroarkkitehtuuri — selkeä opas prosessorin sisäisestä rakenteesta, toimintaperiaatteista, suorituskyvyn optimoinnista ja mikroarkkitehtuurin suhteesta ISA:han.
Tietokonetekniikassa mikroarkkitehtuuri (joskus lyhenne µarch tai uarch) on tietokoneen, keskusyksikön tai digitaalisen signaaliprosessorin sähköisen piirin kuvaus, joka riittää laitteiston toiminnan täydelliseen kuvaamiseen. Mikroarkkitehtuuri määrittelee, miten käskyt toteutetaan laitteistotasolla: mitä rekistereitä, laskenta‑yksiköitä, välimuistikerroksia ja ohjauslogiikkaa prosessorissa on ja miten ne ovat yhteydessä toisiinsa.
Tutkijat käyttävät termiä "tietokoneorganisaatio", kun taas tietokoneteollisuudessa käytetään useammin termiä "mikroarkkitehtuuri". Mikroarkkitehtuuri ja käskysarjaarkkitehtuuri (ISA) muodostavat yhdessä tietokonearkkitehtuurin alan: ISA määrittelee ohjelmoijan näkymän (käskyt, rekisterit, osoitteistus), kun taas mikroarkkitehtuuri kertoo, miten tämä ISA toteutetaan fyysisesti.
Kuvagalleria
1 Kuva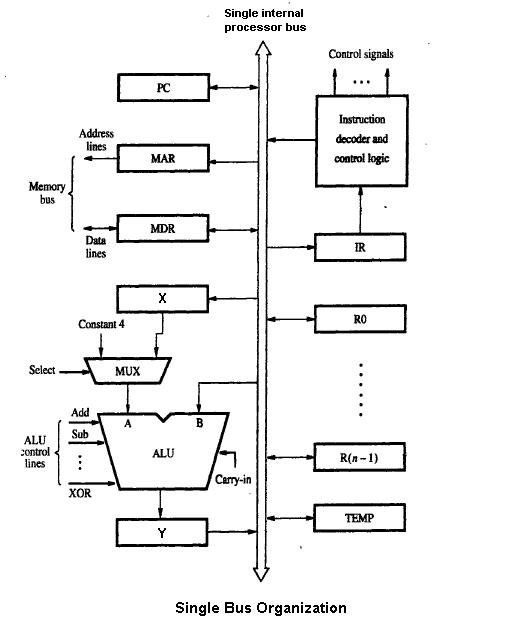
Mitä mikroarkkitehtuuri sisältää?
- Ohjausyksikkö (control unit): tulkitsee käskyjä ja synnyttää ohjaussignaalit eri osille.
- Laskentayksiköt (ALU, FPU): suorittavat aritmeettisia ja loogisia operaatioita.
- Rekisterit: nopeasti osoitettavat tallennuspaikat käskyjen ja väliarvojen säilytykseen.
- Välimuistit (L1, L2, L3) ja TLB: vähentävät muistiviiveitä ja nopeuttavat muistinkäyttöä.
- Pipelining: käskyjen hajauttaminen peräkkäisiin vaiheisiin läpiprosessointia varten.
- Haarauksen ennustus (branch prediction) ja speculative execution: suoritusajan optimointeja häiriöiden vähentämiseksi.
- Superskalaari ja out‑of‑order‑suoritus: useiden käskyjen samanaikainen suorittaminen ja riippuvuuksien hallinta.
- Microcode tai kovakoodattu ohjaus: käskyjen toteutustapa (ohjelmallinen mikrokoodi vs. staattinen logiikka).
Suunnitteluratkaisut ja niiden vaikutukset
Mikroarkkitehtuuriset valinnat vaikuttavat suoraan suorituskykyyn, energiatehokkuuteen, piiripintaan (die size) ja kustannuksiin. Esimerkiksi pitkälle pipeloinnin ja moniydinarkkitehtuurin avulla saavutetaan korkea suorituskyky, mutta ne lisäävät suunnittelun monimutkaisuutta ja virheiden mahdollisuutta. Toisaalta sulautetuissa järjestelmissä käytetään usein yksinkertaisempia mikroarkkitehtuureja, jotka priorisoivat pienen virrankulutuksen ja deterministisen toiminnan.
Tyypillisiä optimointitekniikoita
- Pipelining: jakaa käskyn suorituksen vaiheisiin (esim. hakeminen, tulkinta, suoritus, muistioperaatio, kirjoitus) ja käynnistää uuden käskyn joka vaiheessa.
- Hazardien hallinta: data-, kontrolli‑ ja rakenteellisten häiriöiden (hazardien) tunnistus ja ratkaisut, kuten forwarding ja stall‑mekanismit.
- Haarauksen ennustus: vähentää ohjaushäiriöitä arvioimalla haarojen todennäköisyyksiä.
- Out‑of‑order‑suoritus: käskyjä suoritetaan loogisessa järjestyksessä riippuvuudet huomioiden, mikä parantaa resurssien käyttöä.
- Välimuistohierarkia: useita tasoja (L1−L3) ja optimointeja, kuten peruskaappaaminen (cache associativity) ja rinnakkaiskirjoitukset (write policies).
Mikroarkkitehtuurin ja ISA:n suhde
Käskysarjaarkkitehtuuri (ISA) määrittää käskyt, rekisterit ja toimintoihin liittyvän ohjelmointorajapinnan. Sama ISA voidaan toteuttaa useilla eri mikroarkkitehtuureilla: esimerkiksi x86‑ISA:ta on toteutettu sekä yksinkertaisilla että erittäin monimutkaisilla mikroarkkitehtuureilla (mm. µop‑dekoodaus, mikrokoodi, out‑of‑order‑yksiköt). ISA tarjoaa ohjelmalle yhdenmukaisen käyttöliittymän, kun taas mikroarkkitehtuuri tarjoaa optimoinnit ja toteutuksen, joka voi muuttua sukupolvien välillä säilyttäen ISA‑yhteensopivuuden.
Mikroarkkitehtuurin toteutus
Mikroarkkitehtuurin toteutus voi olla täysin integroitua piirisuunnittelua (ASIC), ohjelmoitavaa logiikkaa (FPGA) tai esisuunniteltuja ydinmoduuleja. Suunnittelussa käytetään laajasti simulaatiota, RTL‑koodia (Verilog/VHDL), syntetisointia ja laitteistokohtaista verifikaatiota varmistaakseen toiminnan ja suoritusarvot. Testaus ja validointi ovat kriittisiä, koska pienet virheet voivat johtaa vakaviin ohjelmistovirheisiin tai tietoturvariskeihin.
Esimerkkejä ja sovelluksia
Mikroarkkitehtuurit vaihtelevat suuresti: mobiililaitteiden energiatehokkaat ARM‑pohjaiset ydintoteutukset, suurten palvelinprosessoreiden moniydin‑ ja laajennetut välimuistiratkaisut sekä DSP‑järjestelmien signaaliprosessointiin optimoidut rakenteet. Myös RISC‑periaatteet (yksinkertaisempia käskyjä ja nopeaa pipeliningia) ja CISC‑arkkitehtuurit (monimutkaisemmat käskyt ja mahdollinen mikrokoodaus) näkyvät mikroarkkitehtuurisina eroja.
Haasteet ja kehitys
Mikroarkkitehtuurin kehitys kohtaa jatkuvasti uusia haasteita: energiatehokkuuden parantaminen, lämpöjohtaminen, moniydinin ajoituksen hallinta, tietoturva‑ominaisuudet (esim. spekulaatioon liittyvät haavoittuvuudet) sekä erikoistettujen kiihdyttimien integrointi (GPU, NPU). Myös arkkitehtuuristen paradigmojen, kuten RISC‑V:n avoimuus, tai heterogeenisten järjestelmien (CPU + GPU + NPU) kasvu muokkaavat mikroarkkitehtuurin suunnittelua.
Yhteenvetona mikroarkkitehtuuri on se laitteistollinen “sydän” joka muuttaa käskysarjan konkreettiseksi toiminnaksi, ja sen valinnat määrittävät pitkälti, kuinka tehokkaasti ja luotettavasti tietokonejärjestelmä toimii käytännössä.
Termin alkuperä
Tietokoneissa on käytetty ohjauslogiikan mikroohjelmointia 1950-luvulta lähtien. Keskusyksikkö purkaa ohjeet ja lähettää signaalit transistorikytkimien avulla asianmukaisia reittejä pitkin. Mikroohjelmasanojen sisällä olevat bitit ohjasivat prosessoria sähköisten signaalien tasolla.
Termiä: mikroarkkitehtuuri käytettiin kuvaamaan yksiköitä, joita mikroohjelmasanat ohjasivat, toisin kuin termiä: "arkkitehtuuri", joka oli näkyvissä ja dokumentoitu ohjelmoijille. Vaikka arkkitehtuurin oli yleensä oltava yhteensopiva eri laitteistosukupolvien välillä, taustalla olevaa mikroarkkitehtuuria voitiin helposti muuttaa.
Suhde käskykanta-arkkitehtuuriin
Mikroarkkitehtuuri liittyy käskykanta-arkkitehtuuriin, mutta ei ole sama kuin käskykanta-arkkitehtuuri. Ohjekokonaisuusarkkitehtuuri on lähellä prosessorin ohjelmointimallia, jonka assemblerikielen ohjelmoija tai kääntäjä näkee ja johon kuuluvat muun muassa suoritusmalli, prosessorirekisterit, muistin osoitetilat, osoite- ja dataformaatit. Mikroarkkitehtuuri (tai tietokoneen organisaatio) on pääasiassa alemman tason rakenne, ja siksi se hallitsee monia yksityiskohtia, jotka ovat piilossa ohjelmointimallissa. Siinä kuvataan prosessorin sisäiset osat ja se, miten ne toimivat yhdessä toteuttaakseen arkkitehtuurin määrittelyn.
Mikroarkkitehtuurielementit voivat olla mitä tahansa yksittäisistä logiikkaporteista rekistereihin, hakutaulukoihin, multipleksaattoreihin, laskureihin jne., kokonaisiin ALU-yksiköihin, FPU-yksiköihin ja vielä suurempiin elementteihin. Elektronisten piirien taso voidaan puolestaan jakaa transistoritason yksityiskohtiin, kuten siihen, mitä porttien perusrakenteita käytetään ja mitä logiikan toteutustyyppejä (staattinen/dynaaminen, vaiheiden määrä jne.) valitaan, sekä varsinaiseen logiikkasuunnitteluun, jota käytetään niiden rakentamiseen.
Muutama tärkeä seikka:
- Yhdellä mikroarkkitehtuurilla, erityisesti jos se sisältää mikrokoodia, voidaan toteuttaa monia eri käskykokonaisuuksia ohjausvarastoa muuttamalla. Tämä voi kuitenkin olla melko monimutkaista, vaikka sitä yksinkertaistettaisiinkin mikrokoodilla ja/tai ROM- tai PLA-piirien taulukkorakenteilla.
- Kahdella koneella voi olla sama mikroarkkitehtuuri ja siten sama lohkokaavio, mutta täysin erilaiset laitteistototeutukset. Tämä koskee sekä elektronisen piirin tasoa että vielä enemmän valmistuksen fyysistä tasoa (sekä integroitujen piirien että erillisten komponenttien osalta).
- Eri mikroarkkitehtuurilla varustetuilla koneilla voi olla sama käskykanta-arkkitehtuuri, joten molemmat koneet pystyvät suorittamaan samoja ohjelmia. Uusien mikroarkkitehtuurien ja/tai piiriratkaisujen sekä puolijohdevalmistuksen edistymisen ansiosta prosessoreiden uudemmat sukupolvet voivat saavuttaa suuremman suorituskyvyn.
Yksinkertaistetut kuvaukset
Hyvin yksinkertaistettu korkean tason kuvaus - joka on yleinen markkinoinnissa - voi näyttää vain melko perusominaisuudet, kuten väylänleveydet, sekä erityyppiset suoritusyksiköt ja muut suuret järjestelmät, kuten haarautumisen ennakointi ja välimuistit, kuvattuna yksinkertaisina lohkoina - kenties joitakin tärkeitä ominaisuuksia tai piirteitä huomioiden. Joskus mukana voi olla myös joitakin putkirakennetta koskevia yksityiskohtia (kuten nouto, dekoodaus, määritys, suoritus, takaisinkirjoitus).
Mikroarkkitehtuurin näkökohdat
Pipelined datapath on nykyään mikroarkkitehtuurissa yleisimmin käytetty datapath-suunnittelu. Tätä tekniikkaa käytetään useimmissa nykyaikaisissa mikroprosessoreissa, mikrokontrollereissa ja DSP:ssä. Pipelined-arkkitehtuuri mahdollistaa useiden ohjeiden päällekkäisen suorituksen, aivan kuin liukuhihnalla. Putkilinja sisältää useita eri vaiheita, jotka ovat mikroarkkitehtuurin suunnittelussa olennaisia. Tällaisia vaiheita ovat muun muassa käskyn haku, käskyn dekoodaus, suoritus ja takaisin kirjoittaminen. Joihinkin arkkitehtuureihin sisältyy muita vaiheita, kuten muistin käyttö. Putkistojen suunnittelu on yksi keskeisistä mikroarkkitehtuurin tehtävistä.
Suoritusyksiköt ovat myös olennainen osa mikroarkkitehtuuria. Suoritusyksiköihin kuuluvat aritmeettiset logiikkayksiköt (ALU), liukulukuyksiköt (FPU), lataus/varastointiyksiköt ja haarautumisen ennakointi. Nämä yksiköt suorittavat prosessorin operaatiot tai laskutoimitukset. Suoritusyksiköiden lukumäärän, niiden latenssin ja läpäisykyvyn valinta ovat tärkeitä mikroarkkitehtuurin suunnittelutehtäviä. Järjestelmän muistien koko, latenssi, läpäisykyky ja liitettävyys ovat myös mikroarkkitehtuuripäätökset.
Järjestelmätason suunnittelupäätökset, kuten se, sisällytetäänkö järjestelmään oheislaitteita, kuten muistisäätimiä, voidaan katsoa osaksi mikroarkkitehtuurin suunnitteluprosessia. Tähän sisältyvät päätökset näiden oheislaitteiden suorituskyvystä ja liitettävyydestä.
Toisin kuin arkkitehtuurisuunnittelussa, jossa päätavoitteena on tietty suorituskyky, mikroarkkitehtuurisuunnittelussa kiinnitetään enemmän huomiota muihin rajoituksiin. Huomiota on kiinnitettävä esimerkiksi seuraaviin seikkoihin:
- Sirun pinta-ala/kustannukset.
- Virrankulutus.
- Looginen monimutkaisuus.
- Helppo liitettävyys.
- Valmistettavuus.
- Helppo virheenkorjaus.
- Testattavuus.
Mikroarkkitehtuurin käsitteet
Yleisesti ottaen kaikki suorittimet, yhden sirun mikroprosessorit tai monisirutoteutukset, suorittavat ohjelmia suorittamalla seuraavat vaiheet:
- Lue ohje ja purkaa se.
- Etsitään kaikki liitännäistiedot, joita tarvitaan käskyn käsittelyyn.
- Käsittele ohje.
- Kirjoita tulokset ylös.
Tätä yksinkertaiselta näyttävää vaihesarjaa vaikeuttaa se, että muistihierarkia, johon kuuluvat välimuisti, keskusmuisti ja haihtumaton tallennus, kuten kiintolevyt, (jossa ohjelmakäskyt ja tiedot ovat) on aina ollut hitaampi kuin itse prosessori. Vaihe (2) aiheuttaa usein viiveen (prosessorin termein usein "sakkaus"), kun tiedot saapuvat tietokoneen väylän kautta. Paljon on tutkittu malleja, joissa näitä viiveitä vältetään mahdollisimman paljon. Vuosien mittaan suunnittelun keskeisenä tavoitteena on ollut useampien käskyjen suorittaminen rinnakkain, mikä lisää ohjelman tehokasta suoritusnopeutta. Näissä pyrkimyksissä otettiin käyttöön monimutkaisia logiikka- ja piirirakenteita. Aiemmin tällaisia tekniikoita voitiin toteuttaa vain kalliissa suurtietokoneissa tai supertietokoneissa, koska tekniikoiden toteuttamiseen tarvittiin paljon piirirakenteita. Puolijohdevalmistuksen kehittyessä yhä useammat näistä tekniikoista voitiin toteuttaa yhdellä puolijohdesirulla.
Seuraavassa esitellään mikroarkkitehtuuritekniikoita, jotka ovat yleisiä nykyaikaisissa suorittimissa.
Ohjekokonaisuuden valinta
Käskykanta-arkkitehtuurin valinta vaikuttaa suuresti suorituskykyisten laitteiden toteuttamisen monimutkaisuuteen. Vuosien mittaan tietokoneiden suunnittelijat ovat tehneet parhaansa yksinkertaistaakseen käskykokonaisuuksia, jotta suorituskykyisempiä toteutuksia voitaisiin toteuttaa säästämällä suunnittelijoiden vaivaa ja aikaa suorituskykyä parantaviin ominaisuuksiin sen sijaan, että ne tuhlattaisiin käskykokonaisuuden monimutkaisuuteen.
Käskykokonaisuuksien suunnittelu on kehittynyt CISC-, RISC-, VLIW- ja EPIC-tyypeistä. Datan rinnakkaisuutta käsitteleviin arkkitehtuureihin kuuluvat SIMD ja vektorit.
Käskyjen putkijohtaminen
Yksi ensimmäisistä ja tehokkaimmista tekniikoista suorituskyvyn parantamiseksi on komentoputken käyttö. Varhaisissa prosessorimalleissa kaikki edellä mainitut vaiheet suoritettiin yhdessä käskyssä ennen seuraavaan siirtymistä. Suuri osa prosessoripiireistä jätettiin toimettomaksi yksittäisen vaiheen aikana; esimerkiksi käskyn dekoodauspiiri oli toimettomana suorituksen aikana ja niin edelleen.
Suoratoistoputket parantavat suorituskykyä, koska niiden avulla useat käskyt kulkevat prosessorin läpi samanaikaisesti. Samassa perusesimerkissä prosessori aloittaisi uuden käskyn dekoodauksen (vaihe 1) edellisen käskyn odottaessa tuloksia. Tämä mahdollistaisi sen, että jopa neljä ohjetta olisi "lennossa" samanaikaisesti, jolloin prosessori näyttäisi neljä kertaa nopeammalta. Vaikka yksittäisen käskyn suorittaminen kestää yhtä kauan (vaiheita on edelleen neljä), prosessori kokonaisuutena "vetäytyy" käskyistä paljon nopeammin ja sitä voidaan käyttää paljon suuremmalla kellotaajuudella.
Välimuisti
Sirujen valmistuksen parantuminen mahdollisti sen, että samalle sirulle voitiin sijoittaa enemmän piiriä, ja suunnittelijat alkoivat etsiä tapoja käyttää niitä. Yksi yleisimmistä tavoista oli lisätä piirille yhä enemmän välimuistia. Välimuisti on erittäin nopeaa muistia, muistia, jota voidaan käyttää muutamassa syklissä verrattuna siihen, mitä tarvitaan keskusmuistin kanssa keskustelemiseen. CPU sisältää välimuistiohjaimen, joka automatisoi lukemisen ja kirjoittamisen välimuistista. Jos tieto on jo välimuistissa, se vain "ilmestyy", kun taas jos se ei ole, prosessori "pysähtyy", kun välimuistiohjain lukee sen sisään.
RISC-malleissa välimuistia alettiin lisätä 1980-luvun puolivälissä tai lopussa, usein vain 4 kilotavua. Määrä kasvoi ajan mittaan, ja tyypillisissä suorittimissa on nykyään noin 512 kilotavua, kun taas tehokkaammissa suorittimissa on 1 tai 2 tai jopa 4, 6, 8 tai 12 megatavua, jotka on järjestetty muistihierarkian eri tasoille. Yleisesti ottaen enemmän välimuistia tarkoittaa enemmän nopeutta.
Kätköt ja putkistot sopivat täydellisesti yhteen. Aikaisemmin ei ollut kovin järkevää rakentaa putkistoa, joka toimisi nopeammin kuin piirin ulkopuolisen käteismuistin käyttöviive. Kun sen sijaan käytettiin piirin sisäistä välimuistia, putkilinja pystyi toimimaan välimuistin käyttölatenssin nopeudella, joka on paljon pienempi aika. Tämä mahdollisti sen, että prosessoreiden toimintataajuudet kasvoivat paljon nopeammin kuin sirun ulkopuolisen muistin toimintataajuudet.
Haarautumisen ennakointi ja spekulatiivinen suoritus
Putkilinjan pysähtymiset ja haarojen aiheuttamat tyhjennykset ovat kaksi tärkeintä tekijää, jotka estävät suorituskyvyn parantamisen käskytason rinnakkaistamisen avulla. Siitä hetkestä, kun prosessorin käskyn dekooderi on havainnut, että se on kohdannut ehdollisen haarautumiskäskyn, siihen hetkeen, kun ratkaiseva hyppyrekisterin arvo voidaan lukea, putkisto saattaa pysähtyä useiksi sykleiksi. Keskimäärin joka viides suoritettu käsky on haarautuminen, joten viivytyksen määrä on suuri. Jos haarautuminen tapahtuu, tilanne on vielä pahempi, koska silloin kaikki putkessa olleet seuraavat ohjeet on tyhjennettävä.
Haaraennusteiden ja spekulatiivisen suorituksen kaltaisia tekniikoita käytetään vähentämään näitä haarakohtaisia rangaistuksia. Haarojen ennustamisessa laitteisto tekee valistuneita arvauksia siitä, tehdäänkö tietty haara. Arvauksen perusteella laitteisto voi hakea käskyjä etukäteen odottamatta rekisterin lukemista. Spekulatiivinen suoritus on lisäparannus, jossa ennustettua polkua pitkin kulkeva koodi suoritetaan ennen kuin tiedetään, pitäisikö haara ottaa vai ei.
Järjestyksen ulkopuolinen suoritus
Välimuistien lisääminen vähentää päämuistihierarkiasta haettavien tietojen odottamisesta johtuvien pysähdysten taajuutta tai kestoa, mutta ei poista niitä kokonaan. Varhaisissa malleissa välimuistin puuttuminen pakotti välimuistiohjaimen pysäyttämään prosessorin ja odottamaan. Ohjelmassa voi tietysti olla jokin muu käsky, jonka tiedot ovat käytettävissä välimuistissa kyseisellä hetkellä. Järjestyksen ulkopuolinen suoritus mahdollistaa sen, että tämä valmis käsky voidaan käsitellä, kun vanhempi käsky odottaa välimuistissa, ja järjestelee sitten tulokset uudelleen, jotta näyttäisi siltä, että kaikki tapahtui ohjelmoidussa järjestyksessä.
Superskalaarinen
Vaikka edellä kuvattujen käsitteiden tukemiseen tarvittiin lisää monimutkaisuutta ja portteja, puolijohdevalmistuksen parannukset mahdollistivat pian entistä useampien logiikka-porttien käytön.
Yllä olevassa hahmotelmassa prosessori käsittelee yhden käskyn osia kerrallaan. Tietokoneohjelmat voitaisiin suorittaa nopeammin, jos useita ohjeita käsiteltäisiin samanaikaisesti. Tämä saavutetaan superskalaarisilla prosessoreilla, jotka monistavat toiminnallisia yksiköitä, kuten ALU:ita. Toiminnallisten yksiköiden monistaminen tuli mahdolliseksi vasta, kun integroitujen piirien (joita joskus kutsutaan "die"-piireiksi) pinta-ala ei enää ylittänyt sen rajaa, mitä voitiin luotettavasti valmistaa. 1980-luvun lopulla markkinoille alkoi tulla superskalaarisia malleja.
Nykyaikaisissa malleissa on tavallista, että niissä on kaksi latausyksikköä, yksi tallennusyksikkö (monissa käskyissä ei ole tallennettavia tuloksia), kaksi tai useampia kokonaislukuyksiköitä, kaksi tai useampia liukulukuyksiköitä ja usein jonkinlainen SIMD-yksikkö. Käskyjen antamislogiikka monimutkaistuu lukemalla valtava luettelo käskyjä muistista ja jakamalla ne eri suoritusyksiköille, jotka ovat sillä hetkellä käyttämättömiä. Tulokset kerätään sitten yhteen ja järjestetään uudelleen lopussa.
Rekisterin uudelleennimeäminen
Rekisterien uudelleennimeämisellä tarkoitetaan tekniikkaa, jota käytetään välttämään ohjelman ohjeiden tarpeetonta sarjamuotoista suorittamista, koska kyseiset ohjeet käyttävät samoja rekistereitä uudelleen. Oletetaan, että meillä on kaksi ryhmää ohjeita, jotka käyttävät samaa rekisteriä, yksi ohjejoukko suoritetaan ensin, jotta rekisteri jää toiselle joukolle, mutta jos toiselle joukolle osoitetaan toinen samanlainen rekisteri, molemmat ohjejoukot voidaan suorittaa rinnakkain.
Moniprosessointi ja monisäikeistäminen
Koska CPU:n toimintataajuuden ja DRAM-muistin käyttöaikojen välinen ero kasvoi, yksikään tekniikka, jolla parannetaan käskytason rinnakkaisuutta (ILP) yhden ohjelman sisällä, ei pystynyt poistamaan pitkiä viiveitä, joita esiintyi, kun tietoja piti hakea keskusmuistista. Lisäksi kehittyneempien ILP-tekniikoiden edellyttämät suuret transistorimäärät ja korkeat toimintataajuudet edellyttivät tehonhäviötasoja, joita ei enää voitu jäähdyttää halvalla. Näistä syistä uudemmat tietokonesukupolvet ovat alkaneet hyödyntää korkeampia rinnakkaistasoja, jotka ovat olemassa yksittäisen ohjelman tai ohjelmasäikeen ulkopuolella.
Tämä suuntaus tunnetaan joskus nimellä "throughput computing". Tämä ajatus sai alkunsa suurtietokonemarkkinoilta, joilla verkkotapahtumien käsittelyssä korostettiin yhden tapahtuman suoritusnopeuden lisäksi kykyä käsitellä suuria määriä tapahtumia samanaikaisesti. Koska tapahtumapohjaiset sovellukset, kuten verkon reititys ja verkkosivujen palveleminen, ovat lisääntyneet huomattavasti viime vuosikymmenen aikana, tietokoneteollisuus on painottanut uudelleen kapasiteetti- ja läpimenokysymyksiä.
Rinnakkaistoiminnot voidaan toteuttaa muun muassa moniprosessorijärjestelmien eli tietokonejärjestelmien avulla, joissa on useita suorittimia. Aikaisemmin tämä oli varattu huippuluokan suurteholaskentajärjestelmille, mutta nykyään pienimuotoiset (2-8) moniprosessoripalvelimet ovat yleistyneet pienyritysten markkinoilla. Suurissa yrityksissä suuret (16-256) moniprosessorit ovat yleisiä. Jopa monisuorittimilla varustettuja henkilökohtaisia tietokoneita on ilmestynyt 1990-luvulta lähtien.
Puolijohdetekniikan kehitys on pienentänyt transistorien kokoa, ja on ilmestynyt moniydinsuoritinyksiköitä, joissa useita suoritinyksiköitä on toteutettu samalla piipiirillä. Alun perin niitä käytettiin sulautetuille markkinoille suunnatuissa siruissa, joissa yksinkertaisemmat ja pienemmät suorittimet mahdollistivat useiden suoritinten sijoittamisen yhdelle piikappaleelle. Vuoteen 2005 mennessä puolijohdeteknologia mahdollisti kahden huippuluokan työpöytäprosessorin CMP-sirujen valmistamisen volyyminä. Joissakin malleissa, kuten UltraSPARC T1:ssä, käytettiin yksinkertaisempia (skalaarisia, in-order) malleja, jotta useampi prosessori saatiin mahtumaan yhdelle piikappaleelle.
Viime aikoina toinen tekniikka, josta on tullut yhä suositumpi, on monisäikeistäminen. Monisäikeistämisessä prosessorin on haettava dataa hitaasta järjestelmämuistista, mutta sen sijaan, että se odottaisi datan saapumista, prosessori vaihtaa toiseen ohjelmaan tai ohjelmasäikeeseen, joka on valmis suoritettavaksi. Vaikka tämä ei nopeuta tiettyä ohjelmaa tai säiettä, se lisää järjestelmän yleistä läpäisykykyä vähentämällä prosessorin joutokäyntiaikaa.
Käsitteellisesti monisäikeistäminen vastaa käyttöjärjestelmän tasolla kontekstinvaihtoa. Erona on se, että monisäikeinen suoritin voi tehdä säikeenvaihdon yhdessä prosessorisyklissä sen sijaan, että kontekstinvaihto vaatisi yleensä satoja tai tuhansia prosessorisyklejä. Tämä saavutetaan kopioimalla tilalaitteisto (kuten rekisteritiedosto ja ohjelmalaskuri) kutakin aktiivista säiettä varten.
Toinen parannus on samanaikainen monisäikeistäminen. Tämän tekniikan avulla superskaaliset suorittimet voivat suorittaa eri ohjelmien/säikeiden ohjeita samanaikaisesti samassa syklissä.
Aiheeseen liittyvät sivut
- Mikroprosessori
- Mikrokontrolleri
- Moniydinprosessori
- Digitaalinen signaaliprosessori
- CPU-suunnittelu
- Datapath
- käskytason rinnakkaisuus (ILP)
Kysymyksiä ja vastauksia
K: Mitä on mikroarkkitehtuuri?
A: Mikroarkkitehtuuri on tietokoneen, keskusyksikön tai digitaalisen signaaliprosessorin sähköisen piirin kuvaus, joka riittää laitteiston toiminnan täydelliseen kuvaamiseen.
K: Miten tutkijat viittaavat tähän käsitteeseen?
V: Tutkijat käyttävät mikroarkkitehtuurista termiä "tietokoneen organisaatio".
K: Miten tietokoneteollisuudessa työskentelevät viittaavat tähän käsitteeseen?
V: Tietokoneteollisuudessa puhutaan useammin mikroarkkitehtuurista, kun puhutaan tästä käsitteestä.
K: Mitkä kaksi alaa muodostavat tietokonearkkitehtuurin?
V: Mikroarkkitehtuuri ja käskysarjaarkkitehtuuri (ISA) muodostavat yhdessä tietokonearkkitehtuurin.
K: Mitä ISA tarkoittaa?
V: ISA tarkoittaa käskykanta-arkkitehtuuria.
K: Mitä tarkoittaa µarch? V: µArch tarkoittaa mikroarkkitehtuuria.
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Mikroarkkitehtuuri – prosessorin sisäinen rakenne ja toimintaperiaate Leandro Alegsa
URL: https://fi.alegsaonline.com/art/64586
Lähteet
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture