Zipfin laki — määritelmä ja esimerkit sanataajuuksista
Zipfin laki selitetty: mitä se tarkoittaa, miten sanataajuudet noudattavat 1/n-suhdetta, esimerkit yleisimmistä sanoista ja sovellukset kielessä sekä muissa ilmiöissä.
Zipfin laki on empiirinen laki, joka on muotoiltu matemaattisten tilastojen avulla ja joka on nimetty sen ensimmäisenä ehdottaneen kielitieteilijä George Kingsley Zipfin mukaan. Zipfin laki kuvaa sanojen esiintymistiheyksien järjestystä suuressa tekstiaineistossa: harvinaisimmat sanat ovat hyvin harvinaisia ja muutama erittäin yleinen sana kattaa suuren osan kaikista sanoista.
Kuvagalleria
3 Kuvat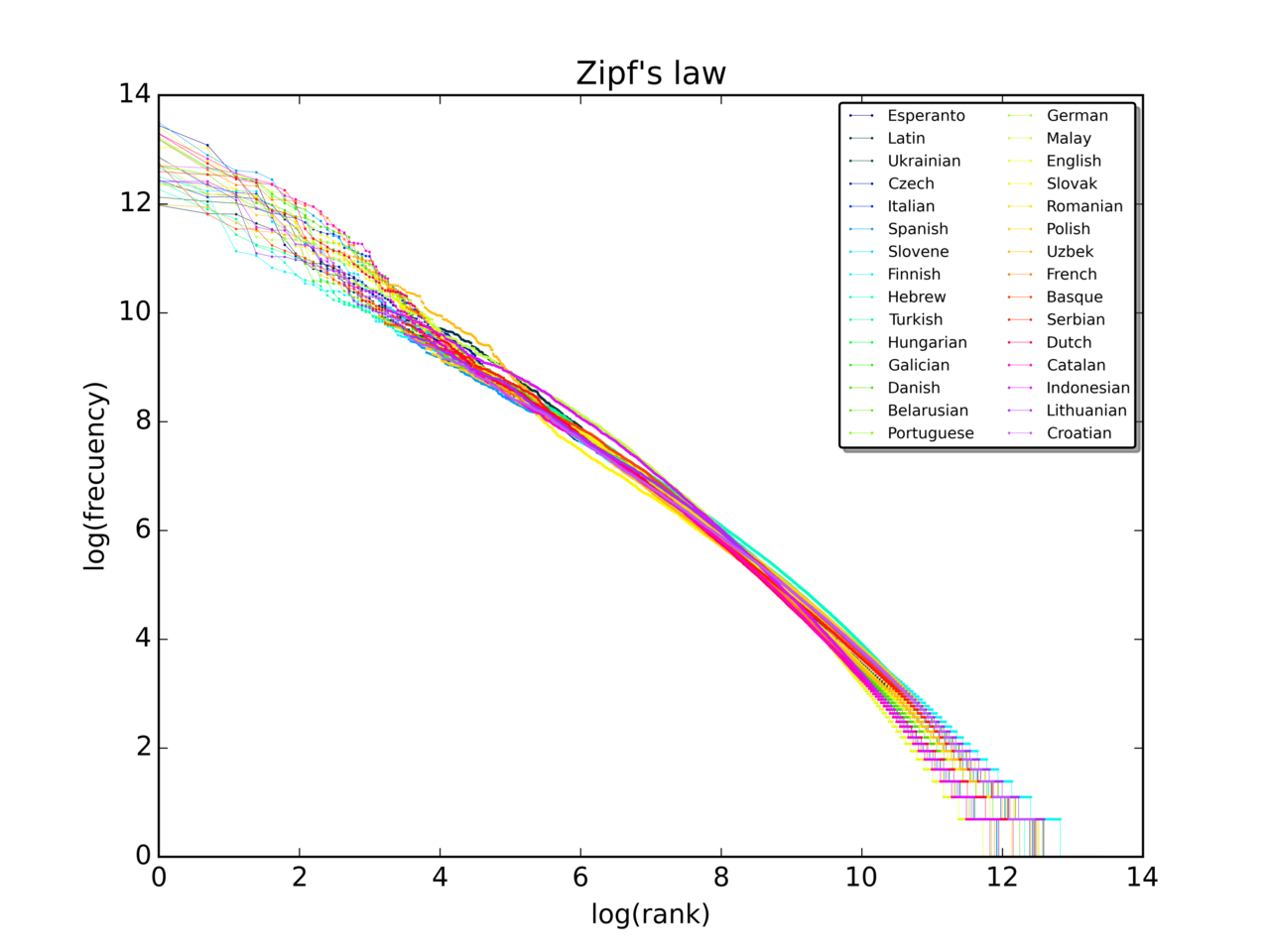


Matemaattinen muoto
Yksinkertaisin muoto esitetään suhteena sanan frekvenssin ja sen sijoituksen välillä frekvenssijärjestyksessä. Mikäli sana on järjestyksessä sijalla n, sen esiintymistiheys f(n) on likimain verrannollinen 1/n. Yleisömuoto voidaan kirjoittaa myös muodossa
f(n) ≈ C / n^s,
missä C on vakio (riippuu aineistosta) ja s on eksponentti, jota usein havaitaan olevan lähellä 1 (Zipfin alkuperäisessä muotoilussa s = 1). Tarkempi tai joustavampi malli on Zipf–Mandelbrotin malli, jossa käytetään siirtymää (offset) pienillä riveillä, ja monissa aineistoissa s poikkeaa täsmälleen yhdestä.
Esimerkkejä sanataajuuksista
Zipfin laki ennustaa, että yleisin sana esiintyy noin kaksi kertaa niin usein kuin toiseksi yleisin, kolme kertaa niin usein kuin kolmanneksi yleisin jne. Esimerkiksi eräässä englannin kielen sanojen otoksessa useimmin esiintyvä sana "the" on lähes 7 prosenttia kaikista sanoista (69 971 sanaa hieman yli miljoonasta). Zipfin lain mukaisesti toiseksi eniten sanoja on "of" (36 411 esiintymää) ja seuraavaksi eniten "and" (28 852 esiintymää), mikä on hieman yli 3,5 prosenttia sanoista. Tarvitaan vain noin 135 sanaa, jotta puolet suuren otoksen sanoista olisi mukana.
Vastaavia muotoja havaitaan myös muissa kielissä. Suomeksi yleisiä sanoja ovat esimerkiksi "ja", "on", "ei", "että" ja "se" — muutokset kieliopin ja taivutuksen vuoksi sijoitukset voivat poiketa englannin vastaavista, mutta taajuusjakauman muoto säilyy samankaltaisena. Pienemmissä kieliaineistoissa tai hyvin erikoistuneissa teksteissä Zipfin laki voi näkyä heikommin.
Miksi Zipfin laki pätee (ja miksi ei tiedetä varmasti)
Tarkkaa yksiselitteistä selitystä ei ole, ja siksi usein todetaan, että "Ei tiedetä, miksi Zipfin laki pätee useimmissa kielissä." Useita hypoteeseja on kuitenkin esitetty:
- Kielen taloudellisuus / vähimmän vaivan periaate: puhujat ja kirjoittajat pyrkivät kommunikoimaan mahdollisimman vähällä vaivalla, mikä suosii muutamien sanojen runsasta käyttöä.
- Preferential attachment / kasautuva etu: kun sanaa käytetään paljon, sen todennäköisyys tulla käytetyksi uudelleen kasvaa — sama mekanismi tuottaa monia muita voimakasjakautuneita ilmiöitä (esim. verkkojen solmujen astelukuja).
- Stokastiset mallit: yksinkertaiset satunnaismallit (kuten Simonin malli) voivat tuottaa Zipfin kaltaisen jakauman ilman kielellisiä pyrkimyksiä.
- Monitasoinen rakenne: kielen rakenteet, semantiikka ja kontekstuaaliset valinnat yhdessä voivat johtaa samanlaiseen pitkähäntäiseen jakaumaan.
Usein oikean selityksen uskotaan olevan eri tekijöiden yhdistelmä, eikä yksikään malli vielä selitä kaikkia havaintoja täydellisesti.
Poikkeamat ja laajennukset
Zipfin laki ei ole täydellinen lauseke, ja todellisissa aineistoissa havaitaan systemaattisia poikkeamia erityisesti hyvin yleisten ja hyvin harvinaisten sanojen kohdalla. Näihin kuuluvat:
- Alkuosan muutos: yleisimpien sanojen osuudet voivat olla korkeampia tai matalampia kuin yksinkertainen 1/n-malli ennustaa.
- Häntäpään käyttäytyminen: erittäin harvinaisten sanojen esiintyminen voi poiketa mallista johtuen korpuksen koosta tai sanojen rakenteesta.
- Zipf–Mandelbrot-malli lisää parametrin, joka korjaa alkupään siirtymää ja antaa paremman sovituksen monille aineistoille.
Sovellukset ja merkitys
Zipfin lain tunnistaminen ja ymmärtäminen on tärkeää monilla alueilla:
- Luonnollisen kielen käsittely (NLP): sanojen taajuusjakaumat vaikuttavat kielimallien ja sanastojen suunnitteluun sekä tekstin tallennukseen ja indeksointiin.
- Tietohaku ja indeksointi: yleisten sanojen (stop words) käsittely perustuu usein niiden suureen frekvenssiin.
- Tiivistys ja pakkaus: usein käytetyt symbolit voidaan koodata lyhyemmin (Huffman-koodaus ja vastaavat menetelmät hyödyntävät taajuuseroja).
- Sosiaalisten ja taloudellisten järjestelmien analyysi: samanlaiset pitkähäntäiset jakaumat esiintyvät kaupunkien väestöissä, yritysten koossa ja monissa muissa ilmiöissä.
Mittaaminen ja validointi
Zipfin lain testaamiseksi käytetään tyypillisesti log-log -kaaviota, jossa sijoitus (rank) piirretaan vaakasuoralle ja frekvenssi pystysuoralle logaritmisella asteikolla. Zipfin lain tapauksessa pisteet asettuvat likimain suoralle viivalle, jonka kulmakerroin on −s. Sovitusmenetelmiä ovat lineaarinen regressio logaritmeissa sekä monimutkaisemmat tilastolliset testit, jotka arvioivat, onko data todella voimakaslakijakautunut vai parempi sovittaa muilla malleilla.
Lyhyt historia
Zipfin lain kaltaisia havaintoja tehtiin jo ennen Zipfiä: esimerkiksi Felix Auerbach raportoi vuonna 1913, että samankaltainen jakauma esiintyy kaupunkien väestöjärjestyksessä. Zipf muodosti laajemman tulkinnan 1930–1940-luvuilla, minkä jälkeen ilmiötä on tutkittu sekä teoreettisesti että empiirisesti eri aloilla.
Zipfin laki on käytännössä hyödyllinen ja poikkeuksellisen laajalle levinnyt empiirinen ilmiö, mutta sen täydellinen teoreettinen selitys ja rajat ovat yhä osa aktiivista tutkimusta.
Kysymyksiä ja vastauksia
K: Mikä on Zipfin laki?
V: Zipfin laki on empiirinen laki, jonka mukaan sanan esiintymistiheys suuressa otoksessa on kääntäen verrannollinen sen sijoittumiseen esiintymistiheystaulukossa.
K: Kuka ehdotti Zipfin lakia?
V: Zipfin lain ehdotti ensimmäisenä kielitieteilijä George Kingsley Zipf.
K: Miten Zipfin laki selittää sanojen esiintymistiheyden englanninkielisten sanojen otoksessa?
V: Zipfin lain mukaan englannin kielen sanoista koostuvassa otoksessa yleisin sana esiintyy noin kaksi kertaa useammin kuin toiseksi yleisin sana, kolme kertaa useammin kuin kolmanneksi yleisin sana jne. Tämä suuntaus jatkuu sitä mukaa, kun sanan arvoaste laskee.
Kysymys: Kuinka monta prosenttia kaikista sanoista on englanninkielisten sanojen näytteessä useimmin esiintyvän sanan osuus?
V: Eräässä englanninkielisten sanojen näytteessä useimmin esiintyvän sanan ("the") osuus kaikista sanoista on lähes 7 prosenttia.
K: Mikä on suhde puolet näytteestä käsittävien sanojen määrän ja näiden sanojen esiintymistiheyden välillä?
V: Zipfin lain mukaan tarvitaan vain noin 135 sanaa, jotta puolet suuren otoksen sanoista saadaan selville.
K: Missä muissa luokitteluissa Zipfin laki näkyy?
V: Sama suhde, jota Zipfin laki kuvaa sanojen frekvenssissä, esiintyy myös muissa, kieleen liittymättömissä ranking-luokituksissa, kuten eri maiden kaupunkien asukasluvuissa, yritysten koossa ja tuloluokituksissa.
K: Kuka huomasi jakauman esiintymisen kaupunkien väestöjärjestyksissä?
V: Felix Auerbach huomasi ensimmäisenä vuonna 1913, että kaupunkien asukasluvun mukaan määräytyvässä paremmuusjärjestyksessä esiintyy jakauma.
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Zipfin laki — määritelmä ja esimerkit sanataajuuksista Leandro Alegsa
URL: https://fi.alegsaonline.com/art/110649
Lähteet
- books.google.com : P. 139