Suurten lukujen laki: tilastotieteen selitys ja nopanheittoesimerkki
Suurten lukujen laki selitetään selkeästi tilastotieteen näkökulmasta nopanheittoesimerkillä — miten havaintojen keskiarvo vakiintuu odotusarvon 3,5 ympärille.
Suurten lukujen laki (LLN) on tilastotieteen lause. Tarkastellaan jotakin prosessia, jossa esiintyy satunnaisia tuloksia, esimerkiksi samaa satunnaismuuttujaa havaitaan toistuvasti. Tällöin havaittujen arvojen näytteiden keskiarvo käyttäytyy ennustettavasti: pitkällä aikavälillä havaittujen arvojen keskiarvo tulee yhä lähemmäksi satunnaismuuttujan odotusarvoa. Tämä on LLN:n perusajatus.
Muodollisemmin voidaan sanoa, että jos X1, X2, ... ovat riippumattomia ja identtisesti jakautuneita (i.i.d.) satunnaismuuttujia, joilla on loppuhyväksytty odotusarvo μ = E[X1], niin otoskeskiarvo
X̄n = (X1 + X2 + ... + Xn) / n
konvergoituu arvoon μ, kun havaintojen lukumäärä n → ∞. On kaksi yleisesti käytettyä muotoa:
- Heikko suurten lukujen laki (convergence in probability): X̄n → μ todennäköisyydessä.
- Vahva suurten lukujen laki (almost sure convergence): X̄n → μ melkein varmasti (eli poikkeuksellinen tapahtumasarja on todennäköisyydeltään nolla).
Kuvagalleria
3 Kuvat


Millä ehdoilla laki pätee?
Perusehto on, että jokaisella havaittavalla muuttujalla on lopullinen odotusarvo (E[X] on äärellinen). Useimmin oletetaan myös riippumattomuus ja identtinen jakauma, mutta on olemassa versioita, jotka sallivat heikompia riippuvuuksia tai hieman vaihtelevia jakaumia. Jos odotusarvoa ei ole (esim. Cauchyn jakauma), LLN ei päde samalla tavalla.
Miksi keskiarvo vakiintuu?
Keskiarvo vakiintuu, koska satunnaisten poikkeamien positiiviset ja negatiiviset vaikutukset kumoavat toisiaan suurilla otoskooilla. Samalla yksittäisten havaintojen vaikutus koko keskiarvoon pienenee — yhden uuden havainnon osuus on 1/n, joten kun n kasvaa, yksittäinen sattuma muuttaa keskiarvoa yhä vähemmän. Käytännössä hajonta näytteiden keskiarvon ympärillä pienenee suhteessa n:n neliöjuureen: tyypillinen ero X̄n ja μ:n välillä on suurusluokkaa σ/√n, missä σ on yksittäisten havaintojen keskihajonta.
Noppaesimerkki
Kun noppaa heitetään, numerot 1, 2, 3, 4, 5 ja 6 ovat mahdollisia tuloksia ja oletetaan, että ne ovat yhtä todennäköisiä. Tulosten populaatiokeskiarvo (tai "odotusarvo") on:
(1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.5.
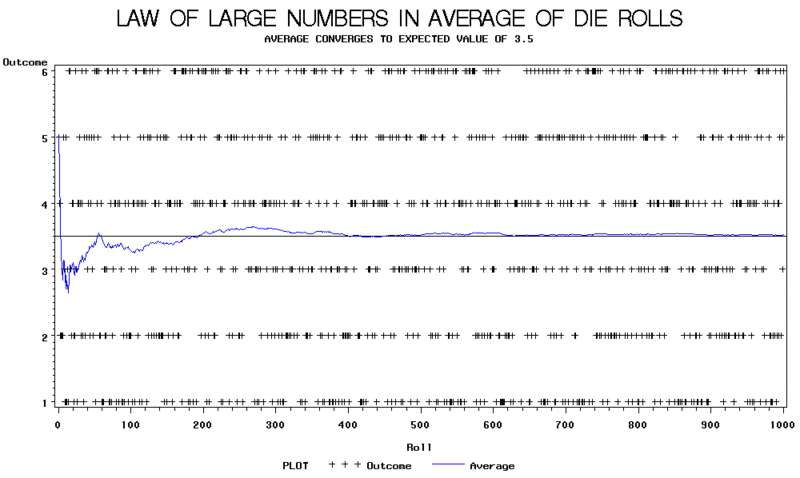
Jos lasketaan nopan tuloksen varianssi, saadaan Var(X) = 35/12 ≈ 2.9167, joten yksittäisen heiton keskihajonta on σ ≈ 1.7078. Näin otoskeskiarvon tyypillinen poikkeama odotusarvosta on noin 1.7078 / √n. Esimerkiksi, jos halutaan että keskiarvo on tyypillisesti korkeintaan 0.1 yksikköä etäällä 3.5:stä, tarvittava otoskoko on suunnilleen n ≈ (1.7078/0.1)^2 ≈ 292. Tämä selittää ilmiön, jonka näkee usein simulaatioissa: alussa keskiarvo hyppii paljon, mutta kun heittojen lukumäärä kasvaa sataan, tuhanteen tai enemmän, keskiarvo vakiintuu yhä lähemmäksi arvoa 3.5.
LLN kertoo siis miksi toistuvissa kokeissa keskiarvo on luotettava estimaatti odotusarvolle, kun otoskoko on riittävän suuri. Tätä täydentää keskeinen raja-arvolause (CLT), joka kuvaa, miten X̄n jakautuu suurilla n:llä (lähestyy normaalijakaumaa, jonka hajonta on σ/√n), ja tarjoaa siten myös tavan arvioida todennäköisyyksiä ja luottamusvälejä.
Historia
Jacob Bernoulli kuvasi ensimmäisenä LLN:n. Hänen mukaansa se oli niin yksinkertainen, että tyhmempikin ihminen tietää vaistomaisesti sen olevan totta. Tästä huolimatta häneltä kesti yli 20 vuotta kehittää hyvä matemaattinen todiste. Kun hän oli löytänyt sen, hän julkaisi todistuksen teoksessa Ars Conjectandi (The Art of Conjecturing) vuonna 1713. Hän nimesi sen "kultaiseksi lauseeksi". Se tuli yleisesti tunnetuksi nimellä "Bernoullin lause" (ei pidä sekoittaa samannimiseen fysiikan lakiin). Vuonna 1835 S.D.Poisson kuvaili sitä edelleen nimellä "La loi des grands nombres" (Suurten lukujen laki). Sen jälkeen se tunnettiin molemmilla nimillä, mutta useimmiten käytetään nimitystä "suurten lukujen laki".
Myös muut matemaatikot vaikuttivat osaltaan lain parantamiseen. Jotkut heistä olivat Tšebyšev, Markov, Borel, Cantelli ja Kolmogorov. Näiden tutkimusten jälkeen laista on nyt olemassa kaksi eri muotoa: Toista kutsutaan "heikoksi" laiksi ja toista "vahvaksi" laiksi. Nämä muodot eivät kuvaa eri lakeja. Niillä on erilaiset tavat kuvata havaitun tai mitatun todennäköisyyden lähentymistä todelliseen todennäköisyyteen. Lain vahva muoto edellyttää heikkoa muotoa.
Kysymyksiä ja vastauksia
K: Mikä on suurten lukujen laki?
A: Suurten lukujen laki on tilastollinen lause, jonka mukaan jos satunnaisprosessia havaitaan toistuvasti, havaittujen arvojen keskiarvo on pitkällä aikavälillä vakaa.
K: Mitä suurten lukujen laki tarkoittaa?
V: Suurten lukujen laki tarkoittaa, että havaintojen määrän kasvaessa havaittujen arvojen keskiarvo tulee yhä lähemmäksi odotusarvoa.
K: Mikä on odotusarvo?
V: Odotusarvo on satunnaisprosessin tulosten populaation keskiarvo.
K: Mikä on odotusarvo, kun heitetään noppaa?
V: Kuution heittämisen odotusarvo on mahdollisten tulosten summa jaettuna tulosten lukumäärällä: (1+2+3+4+5+6)/6=3,5.
K: Mitä tekstissä oleva kuvaaja osoittaa suhteessa suurten lukujen lakiin?
V: Kuvaaja osoittaa, että nopanheittojen keskiarvo vaihtelee aluksi hurjasti, mutta kuten LLN:n laki ennustaa, keskiarvo vakiintuu odotusarvon 3,5 ympärille, kun havaintojen määrä kasvaa suureksi.
K: Miten suurten lukujen lakia sovelletaan nopan heittämiseen?
V: Suurten lukujen laki pätee noppien heittämiseen, koska heittojen määrän kasvaessa heittojen keskiarvo tulee yhä lähemmäksi odotusarvoa 3,5.
K: Miksi suurten lukujen laki on tärkeä tilastotieteessä?
V: Suurten lukujen laki on tärkeä tilastotieteessä, koska se tarjoaa teoreettisen perustan ajatukselle, että tiedoilla on taipumus keskimääräistyä suurella määrällä havaintoja. Se on perusta monille tilastollisille menetelmille, kuten luottamusväleille ja hypoteesin testaukselle.
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Suurten lukujen laki: tilastotieteen selitys ja nopanheittoesimerkki Leandro Alegsa
URL: https://fi.alegsaonline.com/art/56403