Bioinformatiikka: laskennallinen biologia, DNA-tutkimus ja sovellukset
Bioinformatiikka: ymmärrä DNA:n salat laskennallisten menetelmien avulla — genomiikka, data-analyysi ja käytännön sovellukset terveyteen ja tutkimukseen.
Bioinformatiikka tai laskennallinen biologia on suurten biologisten tietomäärien tutkimista. Se keskittyy useimmiten molekyyleihin, kuten DNA:han. Se tehdään useimmiten tietokoneiden avulla.
Bioinformatiikka yhdistää biologiaa, matematiikkaa, tilastotiedettä ja tietojenkäsittelytiedettä. Sen tavoitteena on muuttaa raakadata ymmärrettäväksi tiedoksi: havaita esimerkiksi geenejä, vertailla lajien perimää, tunnistaa mutaatioita tai ennustaa proteiinien kolmiulotteista rakennetta. Tyypillisiä aineistoja ovat genomiset sekvenssit, RNA-lukemat, proteiinidatat ja metagenomiset näytteet.
Tavallisia menetelmiä ja tehtäviä
- Sekvenssien vertailu ja kohdistus (sequence alignment): tunnistaa samanlaisuuksia ja eroja DNA-, RNA- tai proteiinisekvensseissä.
- Genomin koonti (assembly): lyhyistä sekvenssiluukuista rakennetaan pidempiä kontinuita ja lopulta kokonaisia genomisia jaksosia.
- Geenien ja ominaisuuksien ennustus: esimerkiksi geenien sijainnit, promoottorit ja toiminnalliset elementit.
- Geeniekspression analyysi (esim. RNA-seq): mitataan ja verrataan geenien ilmentymistasoja eri olosuhteissa.
- Varianttien tunnistus ja annotointi: yksittäiset nukleotidivariantit (SNP) ja rakennevariantit sekä niiden mahdollinen vaikutus.
- Funktionaalinen analyysi: polkuanalyysit, ontologiat ja proteiiniverkostot auttavat ymmärtämään biologista merkitystä.
- Rakennebiologia: proteiinien ja makromolekyylien kolmiulotteisten rakenteiden ennustus ja mallinnus.
- Metagenomiikka ja mikrobiomitutkimus: monilajisten näytteiden lajikoostumuksen ja toiminnallisen potentiaalin arviointi.
Yleisiä tiedostomuotoja ja työvaiheita
- Raakadatan muodot: FASTQ (sekvenssi + laatu), FASTA (sekvenssi),
- Välitallenteet: BAM/SAM (kohdistetut luet),
- Varianssitiedostot: VCF (variant call format).
- Työputki (pipeline): näytteenoton jälkeinen laadunvalvonta, kohdistus tai koonti, varianttien tunnistus, annotointi ja tulosten visualisointi.
Työkalut ja ympäristöt
- Komennettavat ohjelmat ja kirjastot: BLAST, BWA, Bowtie, GATK, SAMtools.
- Analyysialustat ja paketit: Bioconductor (R), Galaxy (verkkopohjainen), Nextflow ja Snakemake (workflowien hallinta).
- Ohjelmointikielet: Python ja R ovat yleisimpiä; lisäksi käytetään C/C++-pohjaisia tehokkaita työkaluja ja skriptejä.
- Tietokannat: GenBank, Ensembl, UniProt ja muut julkiset resurssit tarjoavat vertailudataa ja annotaatiota.
Sovellukset
- Terveydenhuolto: perinnöllisten sairauksien tunnistus, syöpägenomiikka, tartuntatautien seuranta ja taudinaiheuttajien sekvenssointi.
- Lääkekehitys: kohdeidentifiointi, biomerkkiaineet, farmakogenomiikka ja lääkeaineiden kehitysputket.
- Maatalous ja bioteknologia: kasvin- ja eläinjalostus, kestävä tuotanto ja taudinkestävyyden parantaminen.
- Ekologia ja evoluutio: populaatiogenetiikka, lajien välinen suhde ja biodiversiteetin tutkimus.
- Teollisuus: entsyymien suunnittelu, biojalostamot ja ympäristöbioteknologia.
Haasteet ja eettiset näkökohdat
- Suuri datamäärä vaatii tehokasta tallennusta, laskentakapasiteettia (HPC, pilvi) ja skaalautuvia menetelmiä.
- Tietosuoja ja yksityisyys: ihmisen genomitiedon käsittelyssä on huomioitava henkilötietojen suoja ja eettiset periaatteet.
- Toistettavuus ja standardit: avoin data, metatiedot ja dokumentoidut työputket parantavat tulosten luotettavuutta.
- Tulkinnan vaikeus: tilastollinen merkitsevyys ei aina tarkoita biologista merkitystä, ja väärät johtopäätökset ovat mahdollisia ilman huolellista validointia.
Miten oppia bioinformatiikkaa
- Perusta: biologiaa ja genetiikan perusteet, tilastotiede ja ohjelmointi (Python/R).
- Käytännön harjoittelu: avoimet datasarjat, tehtävät ja online-kurssit sekä työkalujen käyttö (esim. Galaxy, Bioconductor).
- Työskentely workflow-työkalujen ja versionhallinnan kanssa (esim. Git) parantaa reproducibilitya.
- Monialaiset projektit ja yhteistyö biologien, tilastotieteilijöiden ja ohjelmistokehittäjien kanssa ovat hyödyllisiä.
Bioinformatiikka kehittyy nopeasti: koneoppiminen ja tekoäly, suuret populaatiogenomiprojektit sekä entistä tarkemmat single-cell- ja pitkälukuiset sekvensointitekniikat laajentavat mahdollisuuksia. Ala tarjoaa työkaluja perustutkimukseen, soveltavaan biotieteeseen ja terveydenhuollon haasteisiin, mutta edellyttää myös vastuullista ja huolellista tiedon käsittelyä.
Kuvagalleria
10 Kuvat









Säätiö
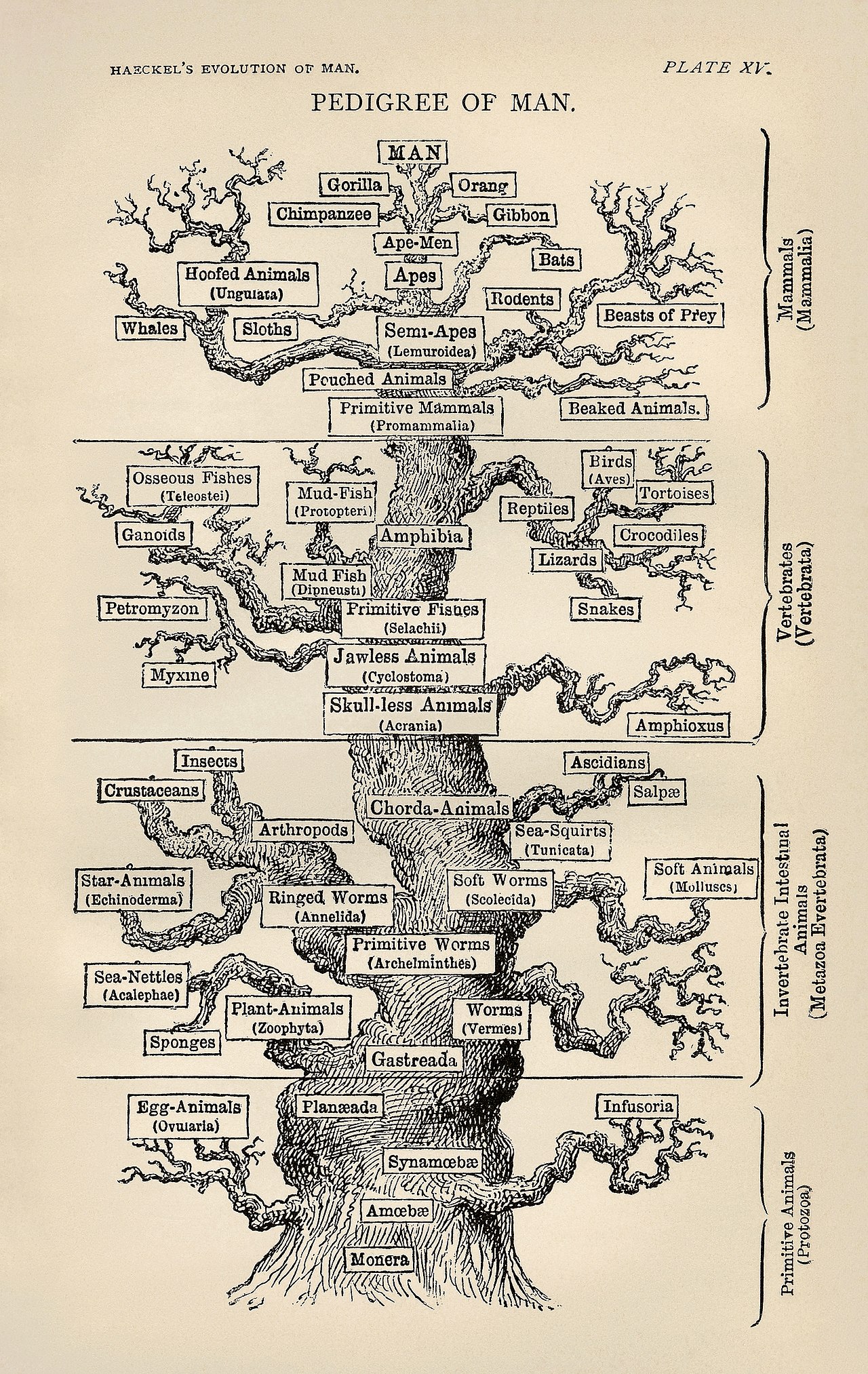
Kun elävien olentojen lajit muuttuvat ajan myötä, niiden solujen sisältämä DNA muuttuu evoluution seurauksena. Jos pystymme poimimaan tiedot nykyisistä elävistä olennoista ja vertaamaan niitä toisiinsa, voimme nähdä, mitkä elävät olennot ovat läheisimmin sukua toisilleen, aivan kuten verrattaessa kahta kirjapainosta, samankaltaisimman voidaan ajatella olevan ajallisesti läheisimmin sukua toisilleen. Näin biologit voivat rakentaa sukupuita eli fylogenioita. Yhdistämällä kaikki puut yhteen voidaan muodostaa kaikki elävät olennot yhdistävä suuri puu, jota kutsutaan "elämänpuuksi". Bioinformatiikka on matemaattisten, tilastollisten ja laskennallisten menetelmien yhdistämistä biologisten, biokemiallisten ja biofysikaalisten tietojen analysoimiseksi.
Prosessi
DNA:han on tallennettu kaikki, mitä solu voi haluta. Kun solu haluaa rakentaa proteiinin, se etsii sopivan DNA-kappaleen, tekee siitä kopion (jota kutsutaan RNA:ksi) ja käyttää kopion ohjeita proteiinin valmistamiseen.
Proteiinit ovat solun "koneisto". Ne voivat suorittaa monia tehtäviä, kuten kuljetuksen, rakenteellisen tuen, liikkeen ja aineenvaihdunnan. Proteiinit koostuvat aminohapoista. On olemassa kaksikymmentä erilaista aminohappoa, joista rakennetaan miljoonia erilaisia proteiinimolekyylejä.
Bioinformatiikan periaatteena on, että näitä molekyylejä voidaan tutkia analysoimalla tietokoneiden avulla DNA-, RNA- ja aminohapposekvenssejä, joista ne on luotu. Koska erilaisia molekyylejä on niin paljon, bioinformatiikka on paras tapa ymmärtää koko järjestelmän toimintaa.
Tietokoneet bioinformatiikassa
Kemistit ovat kehittäneet tapoja ymmärtää pienten molekyylien muotoa ja käyttäytymistä matemaattisen analyysin avulla. He saattavat käyttää tietokoneita (tai jopa vain kynää ja paperia) näiden molekyylien tutkimiseen. Lisäksi vain yhden organismin yhden solun sisältämä DNA on aivan liian suuri, jotta kukaan ihminen voisi sitä lukea, ja DNA:n vertaaminen kahden (tai useamman) organismin välillä, olivatpa ne sitten sisaruksia tai täysin eri lajeja, edellyttää suurten tietomäärien vertaamista pienten (tai suurten) erojen osalta. Tietokoneet soveltuvat paljon paremmin tällaiseen vertailuun, ja tietokoneohjelmoijat ovat tehneet yhteistyötä biologien kanssa luodakseen hyvin suuria tietokantoja, joihin voidaan tallentaa kaikki koskaan opittu DNA-tieto. Biokemistit yrittävät nykyään vastata näihin kysymyksiin kehon jokaisen solun osalta:
- Miten tietty proteiini sitoutuu toiseen proteiiniin?
- Mitkä proteiinit rakentuvat tietystä DNA-juosteesta?
- Miten DNA:ta voidaan käyttää geneettisten häiriöiden ja sairauksien pysäyttämiseen?
- Miten solu on muuttunut evoluution aikana?
- Mille sairauksille ihminen on erityisen altis geeniensä perusteella?
Aiheeseen liittyvät sivut
Aiheeseen liittyvät artikkelit
Tekijä
AlegsaOnline.com Bioinformatiikka: laskennallinen biologia, DNA-tutkimus ja sovellukset Leandro Alegsa
URL: https://fi.alegsaonline.com/art/11636